
Structural biology, genomics, and bioinformatics.
Creating and applying computational tools to study biological systems.
Driven by curiosity.
Structural biology, genomics, and bioinformatics.
Creating and applying computational tools to study biological systems.
Driven by curiosity.

View all blogs on Medium









![Thumbnail for Multiscale Simulations Give Insight into the Hydrogen In and Out Pathways of [NiFe]-Hydrogenases from Aquifex aeolicus and Desulfovibrio fructosovorans](/images/papers/multiscale-simulations-nife-hydrogenases.jpg)

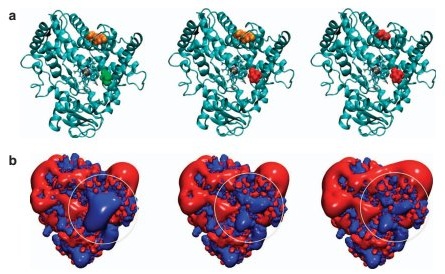


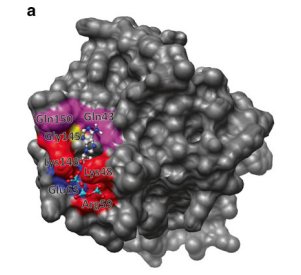


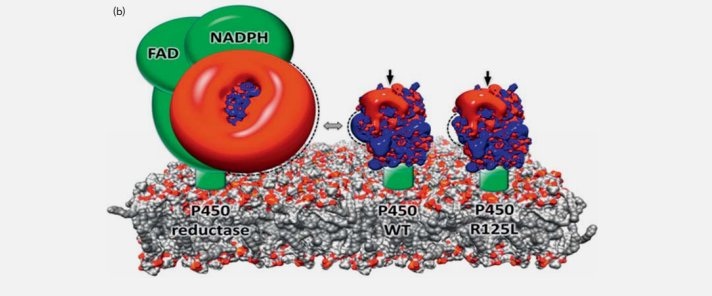
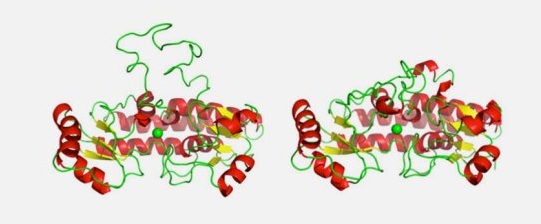


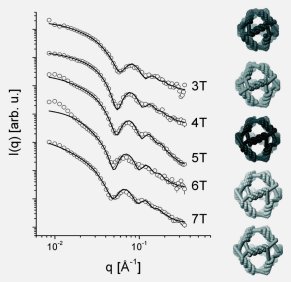
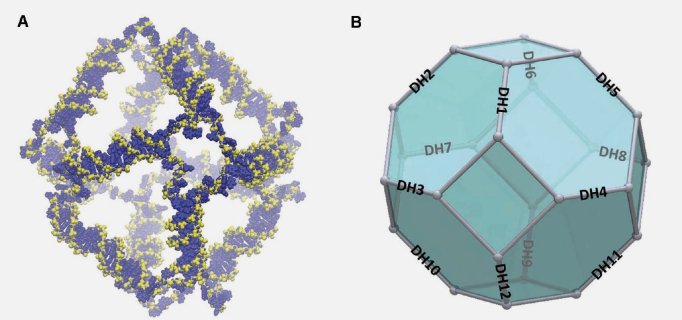
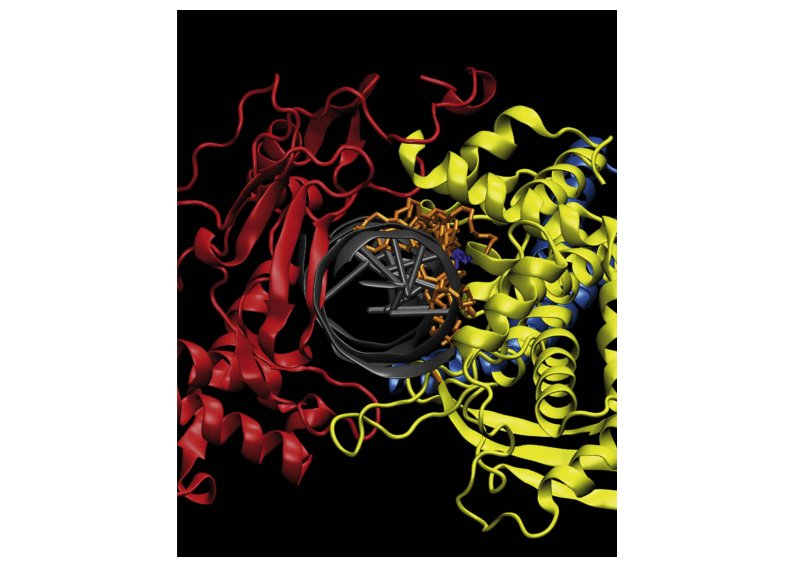
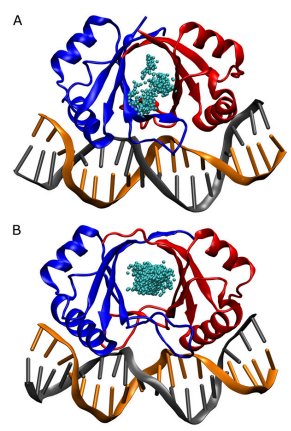
View all publications on Google Scholar