Introduction to Slurm for Biologist transitioning to Computational Biology
Introduction
As a biologist transitioning to computational biology, you're likely using High-Performance Computing (HPC) clusters equipped nowadays with powerful CPUs and GPUs. Correctly use a clusters is crucial for the success of your career. In this series of articles, we will go through the main concepts you need to know to correctly deploy your pipelines on a cluster using Slurm as resource management.
In this first article, I will provide an overview of the HPC cluster architecture and explain how Slurm helps you interact with it.
What is an HPC Cluster?
Even though you don’t necessairly need to know the details of the architecture of a HPC cluster to be a succesfull computational biologist, knowing the big picture will be quite useful to get the most of this systems and troubleshoot some of the issues you may encounter.
An HPC cluster is a system composed of interconnected computers, known as nodes. An HPC cluster is made out by three main kind of nodes: frontend, computing nodes and storage nodes.
- The frontend node is the one you connect to and use to interact with the rest of the platform. Its sole purpose is to allow connection to the cluster, transfer data, and submit jobs to the queue (more about this later) .
- The computing nodes are the ones that actually run the computations. They have significantly more RAM and computational power than the frontend. Typically, their local storage capacity is limited as well. They usuay are equipped with powerful CPUs and nowadays with GPUs.
- The storage nodes host the "hard disk" of the cluster, allowing for flexible management of disk space. Their architecture is typically abstracted, so you don't need to focus on them. The key point to note is that they are not a single hard disk; instead, data is spread across multiple servers. This makes reading or writing data slower. You might be surprised that a job runs slower on an HPC cluster than on your PC. Interaction with storage is pivotal for evaluating and optimizing the performance of your pipeline. For this reason, grasping the intricacies of storage is crucial for the performance of your pipelines. I will discuss these details in a specific article of this series.
Frontend, computing nodes and storage nodes are connected together by a network. You can assimilate this to the wifi box at your home. Just faster. The connection of the nodes is an other important concept you need to grasp to improve the performance of your pipelines.
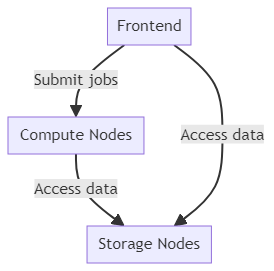
These three different types of nodes interact to perform complex calculations and process large datasets at high speeds. Slurm is part of the backbone of a modern HPC cluster and is crucial for managing shared resources. It lies between the operating system and the user ( i. e. you!) abstracting the management and dispatching of computations, ensuring that resources are allocated efficiently and fairly. It allows you to monitor and remove running jobs as well.
Details
In a computational biology setting, tasks often involve processing large datasets, running complex simulations, or performing extensive data analysis. These tasks can be resource-intensive, requiring significant computational power and time. Here's where a queue management system like Slurm becomes invaluable:
- Resource Allocation: Slurm ensures that computational resources are distributed fairly among users. This prevents any single user from monopolizing the cluster and ensures equitable access.
- Job Prioritization: Not all tasks are created equal. Some jobs may be more urgent than others. Slurm allows for prioritizing jobs based on criteria, defined by the system administrator, such as user or project defined importance, submission time, and resource requirements.
- Optimized Utilization: By managing job queues and scheduling tasks efficiently, Slurm maximizes the utilization of cluster resources, reducing idle times and increasing overall productivity.
- Scalability: As the number of users and computational tasks grows, manual resource management becomes impractical. Slurm's automated scheduling and resource management capabilities scale effortlessly with the increasing demand.
How Does Slurm Work?
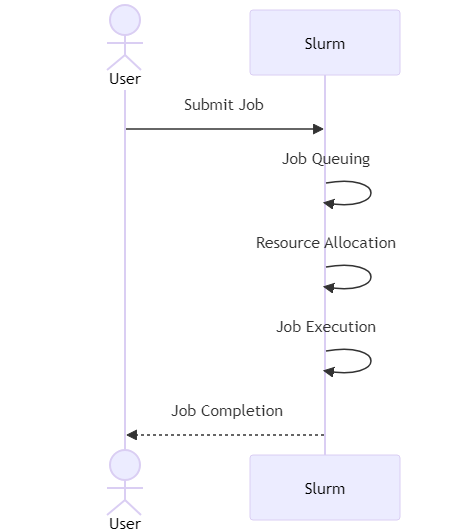
At its core, Slurm works by accepting job submissions from users, placing them in a queue, and then scheduling these jobs based on available resources and predefined policies. Here's a high-level overview of the process:
- Job Submission: Users submit jobs to Slurm using a set of commands. Each job includes information about the required resources (e.g., number of CPUs, memory) and any specific constraints (e.g., time limits, node specifications).
- Job Queuing: Once submitted, jobs are placed in a queue. Slurm evaluates the queue and determines the order in which jobs should be executed based on priority, resource availability, and other scheduling policies.
- Resource Allocation: When the required resources become available, Slurm allocates them to the job. This can involve assigning specific nodes, CPUs, or GPUs to the task.
- Job Execution: The job is executed on the allocated nodes. Slurm monitors the job's progress and manages its execution, ensuring that it runs efficiently.
- Job Completion: Once the job is completed, Slurm releases the resources, making them available for other tasks in the queue.
This steps are performed transparently and you can use the resources using simple commands. In the next few article, I will demistify the most used commands and introduce some advanced usage to make your life easier and more productive.
Practical Considerations
When you transitioning from traditional benchwork to computational biology, understanding and leveraging tools like Slurm allows to have a more your workflows more effective. Here are a few practical considerations to keep in mind:
- Understanding Resource Needs: Before submitting jobs, it's important to have a clear understanding of your resource requirements. This includes the amount of CPU, memory, and storage your task will need.
- Job Dependencies: Some tasks may depend on the completion of others. Slurm allows you to specify job dependencies, ensuring that jobs are executed in the correct order.
- Efficient Coding: Writing efficient code and optimizing your scripts can significantly reduce resource usage and execution time, making it easier to manage large-scale computations.
- Collaboration and Fair Use: Be mindful of other users on the cluster. Collaboration and communication can help ensure that resources are used efficiently and fairly.
In the next articles, I will get into the details of the most important commands. Using practical examples I will show you how to efficiently use slurm.